"Why is the Rust compiler so slow?"
I spent a month repeatedly building my website in Docker, and now have horrors to share.
I've got a problem.
My website (the one you're reading right now) is mainly served by a single Rust binary. For far too long now, every time I wanted to make a change, I would:
- Build a new statically linked binary (with
--target=x86_64-unknown-linux-musl) - Copy it to my server
- Restart the website
This is... not ideal.
So instead, I'd like to switch to deploying my website with containers (be it Docker, Kubernetes, or otherwise), matching the vast majority of software deployed any time in the last decade.
The only issue is that fast Rust builds with Docker are not simple.
Update (2025-06-27)
I first posted this on Bluesky — there was some good discussion there ❤️
Special thanks to Piotr Osiewicz & Wesley Moore for suggestions that saved a ton more time.
More on those closer to the end.
It was also reposted over on r/rust, r/programming and hackernews. Plenty of entertaining comments, if you're in the mood.
- Basics: Rust in Docker
- What's
rustcdoing for all that time? - Actually asking
rustcthis time - It's time to talk about LTO
- A brief note: 50 seconds is fine, actually!
- Another brief note: Can't we just use incremental compilation?
- Digging deeper: Et tu,
LLVM_module_optimize? - What's LLVM's deal?
- What's in LLVM's trace events?
- Can we make
InlinerPassany faster? - Can we make
OptFunctionany faster? - Putting it together
- Update 2025-06-27
- Final recap
Basics: Rust in Docker
Rust in Docker, the simple way
To get your Rust program in a container, the typical approach you might find would be something like:
FROM rust:1.87-alpine3.22 AS builder
RUN apk add musl-dev
WORKDIR /workdir
COPY . .
# the "package" for my website is "web-http-server".
RUN cargo build --package web-http-server --target=x86_64-unknown-linux-musl
# Only include the binary in the final image
FROM alpine:3.20
COPY /workdir/target/x86_64-unknown-linux-musl/release/web-http-server /usr/bin/web-http-server
ENTRYPOINT ["/usr/bin/web-http-server"]
Unfortunately, this will rebuild everything from scratch whenever there's any change.
In my case, building from scratch takes about 4 minutes (including 10s to download the crates every time).
$ cargo build --release --target=x86_64-unknown-linux-musl --package web-http-server
Updating crates.io index
Downloading crates ...
Downloaded anstream v0.6.18
Downloaded http-body v1.0.1
... many more lines ...
Compiling web-http-server v0.1.0 (/workdir/web-http-server)
Finished `release` profile [optimized + debuginfo] target(s) in 3m 51s
Sure, it could be worse. But I've grown accustomed to speedy local builds, thanks to incremental compilation — I don't want to wait that long on every tiny change!
Rust in Docker, with better caching
Thankfully, there's a tool to help with this!
Luca Palmieri's cargo-chef makes it easy to pre-build all of the dependencies as a separate layer in the docker
build cache, so that changes in your codebase only trigger re-compilation of your codebase (and not your dependencies).
I'll save the detailed explanation for Luca's blog post, but broadly cargo-chef creates a simplified "recipe" file from
the current workspace, which can be "cooked" to cache the dependencies without being invalidated by changes in the
workspace.
My website pulls in a few hundred dependencies, so this should help!
...
FROM ... AS planner
COPY . .
RUN cargo chef prepare --recipe-path=/workdir/recipe.json
FROM ... AS cooker
# NOTE: changes to the project can produce the same "recipe",
# allowing this build stage to be cached.
COPY /workdir/recipe.json recipe.json
RUN cargo chef cook --release --recipe-path=/workdir/recipe.json \
--target=x86_64-unknown-linux-musl
# If recipe.json is the same, 'cooker' will be cached.
# All that's left is compiling the final binary.
FROM cooker AS builder
COPY . .
RUN cargo build --release --package web-http-server \
--target=x86_64-unknown-linux-musl
Unfortunately though, it doesn't have quite the speedup we're looking for — most of the time is still in the final binary:
$ # Build dependencies
$ cargo chef cook --release ...
Updating crates.io index
Downloading crates ...
...
Compiling web-http-server v0.0.1 (/workdir/web-http-server)
Finished `release` profile [optimized + debuginfo] target(s) in 1m 07s
$ # Build the final binary, using cached dependencies
$ cargo build --release ...
Compiling web-http-server v0.1.0 (/workdir/web-http-server)
Finished `release` profile [optimized + debuginfo] target(s) in 2m 50s
Weirdly, only 25% of the time is actually spent on the dependencies! As far as I could tell, my code isn't doing
anything fundamentally unreasonable. It's ~7k lines of gluing together various larger dependencies (axum, reqwest,
tokio-postgres, among others.)
(Just to double-check, I tried running cargo build with --verbose. It really was just a single
invocation of rustc that took almost 3 minutes!)
What's rustc doing for all that time?
Following this excellent post by fasterthanlime, I first tried using cargo --timings to get some more information:
$ cargo build --release --timings ...
Compiling web-http-server v0.1.0 (/workdir/web-http-server)
Timing report saved to /workdir/target/cargo-timings/cargo-timing-20250607T192029.207407545Z.html
Finished `release` profile [optimized + debuginfo] target(s) in 2m 54s
In addition to that cargo-timing-<timestamp>.html file, there's also a cargo-timing.html. We'll
just copy out the canonical version:
...
FROM cooker AS builder
COPY . .
RUN cargo build --timings --release --target=x86_64-unknown-linux-musl --package web-http-server
# NEW: Move the cargo timings to a known location
RUN mv target/cargo-timings/cargo-timing-*.html cargo-timing.html
FROM alpine:3.22
COPY /workdir/target/x86_64-unknown-linux-musl/release/web-http-server /usr/bin/web-http-server
# NEW: Include it in the final image
COPY /workdir/cargo-timing.html cargo-timing.html
And with a little bit of container wrangling...
id="$(docker container create <IMAGE>)"
docker cp "$id:/cargo-timing.html" cargo-timing.html
docker container rm -f "$id"
... we should be able to see what's going on! Let's have a look:
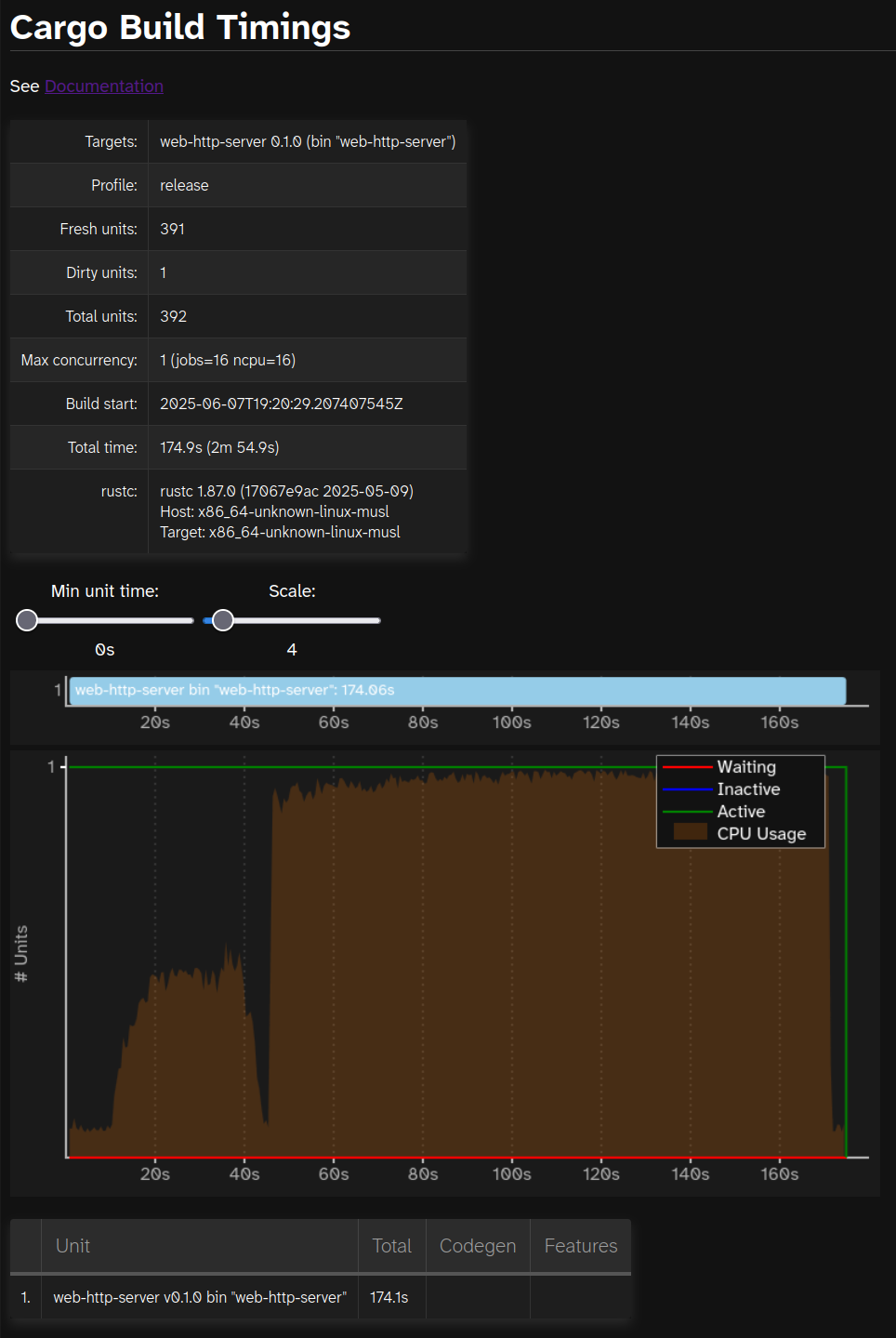
Oh. There's not really much information there!
What's going on here?
cargo build --timings shows a bunch of information about how long each crate took to compile. But here, we only care
about the compilation time of the final crate!
That aside, this does help give us more accurate timing. Measuring outside the compiler adds some extra moving
pieces, or requires searching the output of cargo build — so using cargo's self-reported timings will make more
precise analysis a bit easier, later on.
Just to check, the value here of 174.1s roughly matches the "2m 54s" we saw from the cargo build output.
Actually asking rustc this time
The post from fasterthanlime had one more tip we can use — rustc's self-profiling feature, via the -Zself-profile
flag.
Normally, you'd probably run something like:
RUSTC_BOOTSTRAP=1 cargo rustc --release -- -Z self-profile
(note: This is using cargo rustc to pass extra flags to rustc, with RUSTC_BOOTSTRAP=1 to allow using the -Z
unstable flags on a stable compiler.)
Unfortunately, this won't work here — the change in arguments will invalidate the cached dependencies from
cargo chef cook, and there's no equivalent way to pass additional rustc flags through cargo-chef.
Instead, we can funnel everything via the RUSTFLAGS environment variable:
# cargo chef:
RUSTC_BOOTSTRAP=1 RUSTFLAGS='-Zself-profile' cargo chef cook --release ...
# final build:
RUSTC_BOOTSTRAP=1 RUSTFLAGS='-Zself-profile' cargo build --release ...
This gives us files like web_http_server-<random-number>.mm_profdata, which we can move and extract from the image in
the same way as we did for cargo-timing.html.
(note: It's much easier to automate if we remove the profiling data that was added from cargo chef cook before the
final build. That's omitted here, for brevity.)
Actually using the profdata
The Rust folks maintain a suite of tools for exploring rustc's self-profiling output, over in
https://github.com/rust-lang/measureme.
Some key ones:
summary– produces plaintext output summarizing the profiling dataflamegraph– produces a flamegraph SVGcrox– produces a chrome tracing format trace, compatible withchrome://tracing(in Chromium-based browsers)
But let's install a couple of these to take a look at what we've got:
cargo install --git https://github.com/rust-lang/measureme flamegraph summarize
I personally use Firefox, so we'll hold off on the chrome tracing stuff for now.
First, with summarize (which itself has the summarize and diff subcommands):
$ summarize summarize web_http_server.mm_profdata | wc -l
945
$ summarize summarize web_http_server.mm_profdata | head
+-------------------------------+-----------+-----------------+----------+------------+
| Item | Self time | % of total time | Time | Item count |
+-------------------------------+-----------+-----------------+----------+------------+
| LLVM_lto_optimize | 851.95s | 33.389 | 851.95s | 1137 |
+-------------------------------+-----------+-----------------+----------+------------+
| LLVM_module_codegen_emit_obj | 674.94s | 26.452 | 674.94s | 1137 |
+-------------------------------+-----------+-----------------+----------+------------+
| LLVM_thin_lto_import | 317.75s | 12.453 | 317.75s | 1137 |
+-------------------------------+-----------+-----------------+----------+------------+
| LLVM_module_optimize | 189.00s | 7.407 | 189.00s | 17 |
thread 'main' panicked at library/std/src/io/stdio.rs:1165:9:
failed printing to stdout: Broken pipe (os error 32)
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
(Oops! Classic CLI edge-case. Easy enough to fix, though 😊)
So at a high level, the two biggest things are link-time optimization (LTO) and
LLVM_module_codegen_emit_obj, whatever that is.
Let's see if we can dig a bit deeper with the flamegraph:
$ flamegraph web_http_server.mm_profdata
$ # ... no output. Let's see what it added ...
$ find . -cmin 1 -type f # find files created less than 1 minute ago
./rustc.svg
Cool, we get an SVG!

(It's interactive! If you're curious, you can click through and play around with it yourself.)
So there's presumably some inter-mingling going on between codegen and LTO: codegen_module_perform_lto ends up falling
through to both LLVM_lto_optimize/LLVM_thin_lto_import and LLVM_module_codegen.
But either way, we've got a problem with LTO: codegen_module_perform_lto took ~80% of the total time.
It's time to talk about LTO
The Rust compiler splits up crates into "codegen units", handing each to LLVM as a separate module to compile. In general, optimizations take place within each codegen unit, and then they're linked together at the end.
LTO controls the set of optimizations that LLVM will make during that link-time — for example, inlining or optimization across codegen units.
Cargo (via rustc) exposes a few options for LTO:
- Off — all LTO disabled
- "thin" LTO — in theory, similar performance benefits to "fat" LTO, but less expensive to run
- "fat" LTO — maximum amount of LTO, across all crates at the same time
And if the LTO option is not specified, rustc uses "thin local LTO", which limits "thin" LTO only to a single crate at
a time.
What are the current settings
Turns out that a few years back, I had set lto = "thin" in my Cargo.toml:
[profile.release]
lto = "thin"
debug = "full"
And, while we're at it, debug = "full" enables all debug symbols (where they'd normally be excluded by default for the
release profile). Maybe we should take a look at that as well.
Tweaking the (normal) settings
Let's take a look at the compile times and binary sizes for a variety of lto and debug settings (using
cargo build --timings like before, for more precise timing).
| Time / Size | debug=none | debug=line-tables-only | debug=limited | debug=full |
|---|---|---|---|---|
| LTO disabled | 50.0s / 21.0Mi | 54.4s / 85.9Mi | 54.8s / 105.9Mi | 67.6s / 214.3Mi |
| Thin local LTO | 67.5s / 20.1Mi | 71.5s / 95.4Mi | 73.6s / 117.0Mi | 88.2s / 256.8Mi |
| "Thin" LTO | 133.7s / 20.3Mi | 141.7s / 80.6Mi | 140.7s / 96.0Mi | 172.2s / 197.5Mi |
| "Fat" LTO | 189.1s / 15.9Mi | 211.1s / 64.4Mi | 212.5s / 75.8Mi | 287.1s / 155.9Mi |
At a high level: It seems like the worst cases here are full debug symbols adding 30-50% to the compilation time, and "fat" LTO taking about 4 times longer than with LTO fully disabled.
That mostly tracks with what we'd expect from the documentation — yeah, fat LTO takes longer. But when we disable everything, we're still looking at 50 seconds compiling the final binary!
A brief note: 50 seconds is fine, actually!
Look, 50 seconds is already a great improvement — and if it requires disabling LTO and debug symbols... my website gets approximately zero load. It would be totally fine. It would be perfectly sustainable, even!
There's no practical reason to keep digging here.
But where's the fun in leaving it there? We should be able to do better, right?
Another brief note: Can't we just use incremental compilation?
It's slightly more complicated, but yes, absolutely — for local development, at least. Consistently loading the build
cache isn't straightforward, but you'd want to make the /target directory accessible with a "cache mount" in the
dockerfile, and persist that target directory between builds.
That said, I value that docker build can have a clean environment every time, and I think it's worthwhile to go
through docker's own caching system — which is why I'm using cargo-chef in the first place.
Digging deeper: Et tu, LLVM_module_optimize?
If we disable LTO and debug symbols, compiling the final binary still takes 50 seconds to do... something.
Let's re-run the self-profiling to check out what's going on.

It's ~70% just LLVM_module_optimize — i.e. where LLVM is optimizing the code. Before diving into LLVM itself, let's
see if there's any easier knobs we can tune.
Tuning optimization
The release profile uses opt-level = 3 by default — maybe if we reduce the optimization level, we'll spend less
time on it.
We can actually do one better — since our dependencies are cached, and we only care about the final binary, we can get most of the benefits by only reducing optimizations on the final binary:
[profile.release]
lto = "off"
debug = "none"
opt-level = 0 # Disable optimizations on the final binary
# ... But use a higher opt-level for all dependencies
# See here for more:
# https://doc.rust-lang.org/cargo/reference/profiles.html#overrides
[profile.release.package."*"]
opt-level = 3
Like the previous options, there's a handful of opt-levels we can choose from:
0disables optimizations1,2, and3enable increasing levels of optimizations"s"and"z"are different flavors of prioritizing binary size
Going through a handful of combinations here again:
| Final / Deps | deps: opt-level=3 | deps: opt-level="s" | deps: opt-level="z" |
|---|---|---|---|
final: opt-level=0 | 14.7s / 26.0Mi | 15.0s / 25.9Mi | 15.7s / 26.3Mi |
final: opt-level=1 | 48.8s / 21.5Mi | 47.6s / 20.1Mi | 47.8s / 20.6Mi |
final: opt-level=2 | 50.8s / 20.9Mi | 55.2s / 20.2Mi | 55.4s / 20.7Mi |
final: opt-level=3 | 51.0s / 21.0Mi | 55.4s / 20.3Mi | 55.2s / 20.8Mi |
final: opt-level="s" | 46.0s / 20.1Mi | 45.7s / 18.9Mi | 46.0s / 19.3Mi |
final: opt-level="z" | 42.7s / 20.1Mi | 41.8s / 18.8Mi | 41.8s / 19.3Mi |
Basically:
- The baseline for any level of optimizations on the final binary is about 50 seconds
- If we disable all optimizations, then it's pretty quick: only ~15s
What's LLVM's deal?
Rust relies pretty heavily on optimizations, and while it'd probably be fine to just blanket-disable them for the final binary, it'd be pretty cool if we can at least keep some optimizations!
So let's try to figure out what's taking so long. rustc's self-profiling doesn't give us any more detail though,
so we'll have to get it from LLVM.
There's another couple useful rustc flags here:
-Z time-llvm-passes– emit LLVM profiling information as plaintext-Z llvm-time-trace– emit LLVM profiling information in the chrome tracing format (again with that one!)
Profiling LLVM with rustc — plain text
Like before, let's skip the chrome tracing format for now, and see what we can get from plain text.
# cargo chef:
RUSTC_BOOTSTRAP=1 RUSTFLAGS='-Ztime-llvm-passes' cargo chef cook --release ...
# final build:
RUSTC_BOOTSTRAP=1 RUSTFLAGS='-Ztime-llvm-passes' cargo build --release ...
... Unfortunately if you try to docker build again, you'll immediately hit something like:
[output clipped, log limit 2MiB reached]
This is because BuildKit (if you're using ~recent Docker on Linux) has default output limits that are pretty small.
We can just raise the limits, right?
These limits are configured by the environment variables BUILDKIT_STEP_LOG_MAX_SIZE and BUILDKIT_STEP_LOG_MAX_SPEED.
But if we pass them to docker build with something like this:
BUILDKIT_STEP_LOG_MAX_SIZE=-1 BUILDKIT_STEP_LOG_MAX_SPEED=-1 docker build ...
... it won't work, because the configuration must be set on the docker daemon.
On most Linux distros, dockerd is run as a systemd unit.
So just set it on the systemd unit?
The Proper™ way to do this is by creating an override file – something like:
$ systemctl edit --drop-in=buildkit-env.conf docker.service
(note: passing --drop-in allows naming the file something more descriptive than override.conf)
It opens a new file, where we can set the environment overrides:
[Service]
Environment="BUILDKIT_STEP_LOG_MAX_SIZE=-1"
Environment="BUILDKIT_STEP_LOG_MAX_SPEED=-1"
And once we're done:
$ systemctl restart docker.service
Checking our work...
After restarting, we can double-check the environment with something like:
$ pgrep dockerd
1234567
$ cat /proc/1234567/environ | tr '\0' '\n' | grep -i 'buildkit'
BUILDKIT_STEP_LOG_MAX_SIZE=-1
BUILDKIT_STEP_LOG_MAX_SPEED=-1
(note: tr is needed because the environment is a nul-separated string, and it's easier to search line-by-line)
So after getting unlimited docker build output on the terminal, what's in it?
~200k lines of plaintext — probably not what you want to be copying from your terminal, anyways.
So, redirecting to a file inside docker and copying that out like before, we get a bunch of pass/analysis timing reports. They each look something like this:
===-------------------------------------------------------------------------===
Pass execution timing report
===-------------------------------------------------------------------------===
Total Execution Time: 0.0428 seconds (0.0433 wall clock)
---User Time--- --System Time-- --User+System-- ---Wall Time--- — Name ---
0.0072 ( 19.2%) 0.0015 ( 27.4%) 0.0086 ( 20.2%) 0.0087 ( 20.0%) InstCombinePass
0.0040 ( 10.8%) 0.0006 ( 10.8%) 0.0046 ( 10.8%) 0.0047 ( 10.8%) InlinerPass
0.0024 ( 6.4%) 0.0010 ( 18.0%) 0.0034 ( 7.9%) 0.0034 ( 7.8%) SimplifyCFGPass
0.0022 ( 5.9%) 0.0002 ( 4.5%) 0.0025 ( 5.7%) 0.0024 ( 5.6%) EarlyCSEPass
0.0021 ( 5.5%) 0.0001 ( 1.5%) 0.0021 ( 5.0%) 0.0022 ( 5.0%) GVNPass
0.0015 ( 4.0%) 0.0001 ( 2.2%) 0.0016 ( 3.8%) 0.0018 ( 4.2%) ArgumentPromotionPass
... entries here continue, and more passes below, for hundreds of thousands of lines ...
It certainly is possible to parse and analyze these! But it's also hard to be certain about what you're looking at when each pass execution is emitted separately and multi-threading can interfere with timing.
Let's see if there's a better way to get good data.
Profiling LLVM with rustc — actual tracing this time
We skipped -Z llvm-time-trace earlier because it emits the chrome tracing format.
Let's revisit that:
# cargo chef:
RUSTC_BOOTSTRAP=1 RUSTFLAGS='-Zllvm-time-trace' cargo chef cook --release ...
# final build:
RUSTC_BOOTSTRAP=1 RUSTFLAGS='-Zllvm-time-trace' cargo build --release ...
It produces a bunch of $package-$hash.llvm_timings.json files, alongside the normal compilation artifacts:
$ ls -lAh target/x86_64-unknown-linux-musl/release/deps | head
total 5G
-rw-r--r-- 1 root root 11.8K Jun 9 23:11 aho_corasick-ff268aeac1b7a243.d
-rw-r--r-- 1 root root 69.4M Jun 9 23:11 aho_corasick-ff268aeac1b7a243.llvm_timings.json
-rw-r--r-- 1 root root 6.6K Jun 9 23:11 allocator_api2-28ed2e0fa8ab7b44.d
-rw-r--r-- 1 root root 373.1K Jun 9 23:11 allocator_api2-28ed2e0fa8ab7b44.llvm_timings.json
-rw-r--r-- 1 root root 4.0K Jun 9 23:11 anstream-cf9519a72988d4c1.d
-rw-r--r-- 1 root root 4.4M Jun 9 23:11 anstream-cf9519a72988d4c1.llvm_timings.json
-rw-r--r-- 1 root root 2.4K Jun 9 23:11 anstyle-76a77f68346b4238.d
-rw-r--r-- 1 root root 885.3K Jun 9 23:11 anstyle-76a77f68346b4238.llvm_timings.json
-rw-r--r-- 1 root root 2.2K Jun 9 23:11 anstyle_parse-702e2f8f76fe1827.d
(Why root? Setting up rootless docker didn't work when I tried it a few years back, and I haven't bothered since)
So, deleting *.llvm_timings.json between cargo-chef and the final build, we can extract the singular profile for the
final binary into web_http_server.llvm_timings.json.
There's just one minor hiccup:
$ du -sh web_http_server.llvm_timings.json
1.4G web_http_server.llvm_timings.json
It's enormous. It's also all one single line!
In theory though, a wide variety of tools should be able to process this:
Firefox profiling
I'm using Firefox, so why not Firefox Profiler? It should be able to handle it:
The Firefox Profiler can also import profiles from other profilers, such as Linux perf, Android SimplePerf, the Chrome performance panel, Android Studio, or any file using the dhat format or Google’s Trace Event Format.
Unfortunately, this didn't work:
Looking at the web console, we can see why it failed – it ran out of memory:

perfetto.dev on Firefox
When I searched for displaying these chrome tracing format traces, perfetto.dev was another alternative that came up. It's also maintained by Google.
When I first tried it, I was using a larger trace from a longer compilation, and it ran out of memory as well:
I resorted to running the WASM processor locally, hitting this bug affecting Firefox.
At the time I gave up and used Chromium instead, but in the process of writing this post, I tried it again. The smaller trace allowed it to work:
Either way though, I found I had absolutely no clue how to use this interface – and loading a complex trace from LLVM probably also wasn't the best introduction point.
chrome://tracing on Chromium
You'd be forgiven for expecting this one to work the best out of all the options, but unfortunately it also failed – albeit more amusingly than the others:
![Screenshot of an error pop-up, saying "Error while loading file: [object ProgressEvent]"](/blog/why-rust-compiler-slow/assets/chrome-tracing-err-2025-05-04T17:43:44Z.png)
None of these options worked for me — but it's a big JSON file with a known format, how hard can it be?
Turns out, a 1.4GiB single line of JSON makes all the normal tools complain:
- If you try to view it with
less, scrolling blocks on processing the entire file - If you try to process it with
jq, it has to load the entire 1.4GiB intojq's internal format (which expectedly takes up much more than the original 1.4GiB) - Vim hangs when you open it
- And you probably don't want to just
catit to the terminal — again, it's 1.4GiB!
So instead, we can just look at a few hundred characters, at the start and end of the file:
$ head -c300 web_http_server.llvm_timings.json
{"traceEvents":[{"pid":25,"tid":30,"ts":8291351,"ph":"X","dur":6827,"name":"RunPass","args":{"detail":"Expand large div/rem"}},{"pid":25,"tid":30,"ts":8298181,"ph":"X","dur":2,"name":"RunPass","args":{"detail":"Expand large fp convert"}},{"pid":25,"tid":30,"ts":8298183,"ph":"X","dur":8,"name":"RunPa
$ tail -c300 web_http_server.llvm_timings.json
me":""}},{"cat":"","pid":25,"tid":43,"ts":0,"ph":"M","name":"thread_name","args":{"name":""}},{"cat":"","pid":25,"tid":44,"ts":0,"ph":"M","name":"thread_name","args":{"name":""}},{"cat":"","pid":25,"tid":29,"ts":0,"ph":"M","name":"thread_name","args":{"name":""}}],"beginningOfTime":1749510885820760}
Matching this to the "JSON Object Format" from the chrome tracing spec, it seems we have a single JSON object like:
{
"traceEvents": [
{"pid":25,"tid":30,"ts":8291351,"ph":"X","dur":6827,"name":"RunPass","args":{"detail":"Expand large div/rem"}},
{"pid":25,"tid":30,"ts":8298181,"ph":"X","dur":2,"name":"RunPass","args":{"detail":"Expand large fp convert"}},
...
],
"beginningOfTime": 1749510885820760
}
We'd be able to process it with normal tools if we split each event into its own object. That could be something like:
cat web_http_server.llvm_timings.json \
| sed -E 's/},/}\n/g;s/^\{"traceEvents":\[//g;s/\],"beginningOfTime":[0-9]+}$//g' \
> web-http-server.llvm_timings.jsonl
(i.e.: turn }, into a newline, strip the start of the object, strip the end of the object)
And now we can process this.
$ wc -l web_http_server.llvm_timings.jsonl
7301865 web_http_server.llvm_timings.jsonl
$ head web_http_server.llvm_timings.jsonl
{"pid":25,"tid":30,"ts":8291351,"ph":"X","dur":6827,"name":"RunPass","args":{"detail":"Expand large div/rem"}}
{"pid":25,"tid":30,"ts":8298181,"ph":"X","dur":2,"name":"RunPass","args":{"detail":"Expand large fp convert"}}
{"pid":25,"tid":30,"ts":8298183,"ph":"X","dur":8,"name":"RunPass","args":{"detail":"Expand Atomic instructions"}}
{"pid":25,"tid":30,"ts":8298192,"ph":"X","dur":0,"name":"RunPass","args":{"detail":"Lower AMX intrinsics"}}
{"pid":25,"tid":30,"ts":8298193,"ph":"X","dur":0,"name":"RunPass","args":{"detail":"Lower AMX type for load/store"}}
{"pid":25,"tid":30,"ts":8298195,"ph":"X","dur":1,"name":"RunPass","args":{"detail":"Lower Garbage Collection Instructions"}}
{"pid":25,"tid":30,"ts":8298196,"ph":"X","dur":1,"name":"RunPass","args":{"detail":"Shadow Stack GC Lowering"}}
{"pid":25,"tid":30,"ts":8298197,"ph":"X","dur":1164,"name":"RunPass","args":{"detail":"Remove unreachable blocks from the CFG"}}
{"pid":25,"tid":30,"ts":8299362,"ph":"X","dur":1,"name":"RunPass","args":{"detail":"Instrument function entry/exit with calls to e.g. mcount() (post inlining)"}}
{"pid":25,"tid":30,"ts":8299363,"ph":"X","dur":5,"name":"RunPass","args":{"detail":"Scalarize Masked Memory Intrinsics"}}
What's in LLVM's trace events?
It looks like these events all have "ph":"X".
According to the spec, the ph field gives the type of event, and X refers to "complete" events, recording how long a
particular piece of work took on a given thread (tid). The duration in microseconds is given by dur.
Aside from that, we also have M events:
$ cat web_http_server.llvm_timings.jsonl | jq -c 'select(.ph != "X")' | head
{"cat":"","pid":25,"tid":27,"ts":0,"ph":"M","name":"process_name","args":{"name":"rustc"}}
{"cat":"","pid":25,"tid":27,"ts":0,"ph":"M","name":"thread_name","args":{"name":""}}
{"cat":"","pid":25,"tid":30,"ts":0,"ph":"M","name":"thread_name","args":{"name":""}}
{"cat":"","pid":25,"tid":35,"ts":0,"ph":"M","name":"thread_name","args":{"name":""}}
{"cat":"","pid":25,"tid":32,"ts":0,"ph":"M","name":"thread_name","args":{"name":""}}
{"cat":"","pid":25,"tid":33,"ts":0,"ph":"M","name":"thread_name","args":{"name":""}}
{"cat":"","pid":25,"tid":34,"ts":0,"ph":"M","name":"thread_name","args":{"name":""}}
{"cat":"","pid":25,"tid":39,"ts":0,"ph":"M","name":"thread_name","args":{"name":""}}
{"cat":"","pid":25,"tid":40,"ts":0,"ph":"M","name":"thread_name","args":{"name":""}}
{"cat":"","pid":25,"tid":36,"ts":0,"ph":"M","name":"thread_name","args":{"name":""}}
These are "metadata" events — in our case, not much useful information.
And aside from these, there's nothing else:
$ cat web_http_server.llvm_timings.jsonl | jq -c 'select(.ph != "X" and .ph != "M")'
<nothing>
Going back to those X events — there were a bunch of them with "name":"RunPass". What else do we have?
$ cat web_http_server.llvm_timings.jsonl | jq -c 'select(.ph == "X" and .name != "RunPass")' | head
{"pid":25,"tid":30,"ts":8291349,"ph":"X","dur":32009,"name":"OptFunction","args":{"detail":"_RNvCscSpY9Juk0HT_7___rustc12___rust_alloc"}}
{"pid":25,"tid":30,"ts":8323394,"ph":"X","dur":283,"name":"OptFunction","args":{"detail":"_RNvCscSpY9Juk0HT_7___rustc14___rust_dealloc"}}
{"pid":25,"tid":30,"ts":8323678,"ph":"X","dur":216,"name":"OptFunction","args":{"detail":"_RNvCscSpY9Juk0HT_7___rustc14___rust_realloc"}}
{"pid":25,"tid":30,"ts":8323895,"ph":"X","dur":179,"name":"OptFunction","args":{"detail":"_RNvCscSpY9Juk0HT_7___rustc19___rust_alloc_zeroed"}}
{"pid":25,"tid":30,"ts":8324075,"ph":"X","dur":155,"name":"OptFunction","args":{"detail":"_RNvCscSpY9Juk0HT_7___rustc26___rust_alloc_error_handler"}}
{"pid":25,"tid":30,"ts":8288691,"ph":"X","dur":35693,"name":"OptModule","args":{"detail":"5z12fn0vr5uv0i2pfsngwe5em"}}
{"pid":25,"tid":35,"ts":9730144,"ph":"X","dur":16,"name":"Annotation2MetadataPass","args":{"detail":"[module]"}}
{"pid":25,"tid":35,"ts":9730214,"ph":"X","dur":10,"name":"ForceFunctionAttrsPass","args":{"detail":"[module]"}}
{"pid":25,"tid":35,"ts":9730346,"ph":"X","dur":11,"name":"InnerAnalysisManagerProxy<llvm::AnalysisManager<llvm::Function>, llvm::Module>","args":{"detail":"[module]"}}
{"pid":25,"tid":35,"ts":9730416,"ph":"X","dur":17,"name":"TargetLibraryAnalysis","args":{"detail":"llvm.expect.i1"}}
Neat! It looks like we might be able to demangle some of the symbols to get timings on individual functions.
If we track what's being run and how long it takes, we should be able to get a better sense of why our compile time is so long.
Later on, there's aggregate information for certain types of events, like Total OptFunction. These are equivalent to
the sum of the duration for that event type (in this case, OptFunction). Let's see kind of operations are taking the
most time:
$ cat web_http_server.llvm_timings.jsonl | jq -r 'select(.name | startswith("Total ")) | "\(.dur / 1e6) \(.name)"' | sort -rn | head
665.369662 Total ModuleInlinerWrapperPass
656.465446 Total ModuleToPostOrderCGSCCPassAdaptor
632.441396 Total DevirtSCCRepeatedPass
627.236893 Total PassManager<llvm::LazyCallGraph::SCC, llvm::AnalysisManager<llvm::LazyCallGraph::SCC, llvm::LazyCallGraph&>, llvm::LazyCallGraph&, llvm::CGSCCUpdateResult&>
536.738589 Total PassManager<llvm::Function>
372.768547 Total CGSCCToFunctionPassAdaptor
193.914869 Total ModuleToFunctionPassAdaptor
190.924012 Total OptModule
189.621119 Total OptFunction
182.250077 Total InlinerPass
This particular run took ~110 seconds on a 16-core machine, so it's clear that some passes are being double-counted
(which makes sense — we see both ModuleInlinerWrapperPass and InlinerPass, and it looks like OptModule
probably just calls OptFunction).
But broadly, it seems like optimization (OptFunction) and inlining (InlinerPass) are the two parts taking a lot of
time — let's see if we can do anything about it.
Can we make InlinerPass any faster?
Hopefully, yes!
LLVM has a bunch of arguments that can be configured, which rustc exposes through the -C llvm-args flag. At time of
writing (June 2025), there's somewhere in the region of ~100 options that mention inlining (via rustc -C llvm-args='--help-list-hidden').
In particular, there's a bunch of relevant options in the file controlling the cost analysis.
Now, I'll be honest, I know very little about LLVM's inlining. Most of the options refer to the "cost" associated with the inlining, or with the function being inlined, etc. I'm flying mostly bind here. But there's a few arguments that seem like decent candidates for tuning:
--inlinedefault-threshold=225— "Default amount of inlining to perform"--inline-threshold=225— "Control the amount of inlining to perform"--inlinehint-threshold=325— "Threshold for inlining functions with inline hint"
For all of these, the "threshold" roughly means "allow inlining functions with cost below the threshold", so a higher threshold means more inlining.
So if we set all of these to some value (e.g., 50), we should see that there's less inlining, and in turn faster
compile times.
Something like:
RUSTFLAGS="-Cllvm-args=-inline-threshold=50 -Cllvm-args=-inlinedefault-threshold=50 -Cllvm-args=-inlinehint-threshold=50" ...
(Why separate -C llvm-args? I couldn't find a way to make the whitespace happy through the RUSTFLAGS environment
variable — maybe it's possible if you set build.rustflags in .cargo/config.toml, but this solution worked 🤷)
In any case, reducing to a threshold of 50 does end up faster! About 42.2s, down from 48.8s.
Here's what that looks like across a handful of values:

(note: The smallest value is 1, and not zero. Why 1? Sometimes zero has special behavior – setting to one seemed like a safer bet.)
Of these, it's hard to say exactly what the best value is, but for my use case (remember: my website gets ~zero load!), setting the thresholds to 10 looks promising. We'll hold off on that for now though.
Can we make OptFunction any faster?
Optimizing functions was the other expensive task we saw.
The knobs here are much less clear to me (we're already at opt-level = 1, and opt-level = 0 completely disables
optimizations). So, let's see what exactly is taking so long.
First, a brief look at the event format:
$ cat web_http_server.llvm_timings.jsonl | jq -c 'select(.name == "OptFunction")' | head
{"pid":25,"tid":30,"ts":7995006,"ph":"X","dur":32052,"name":"OptFunction","args":{"detail":"_RNvCscSpY9Juk0HT_7___rustc12___rust_alloc"}}
{"pid":25,"tid":30,"ts":8027059,"ph":"X","dur":242,"name":"OptFunction","args":{"detail":"_RNvCscSpY9Juk0HT_7___rustc14___rust_dealloc"}}
{"pid":25,"tid":30,"ts":8027302,"ph":"X","dur":158,"name":"OptFunction","args":{"detail":"_RNvCscSpY9Juk0HT_7___rustc14___rust_realloc"}}
{"pid":25,"tid":30,"ts":8027461,"ph":"X","dur":126,"name":"OptFunction","args":{"detail":"_RNvCscSpY9Juk0HT_7___rustc19___rust_alloc_zeroed"}}
{"pid":25,"tid":30,"ts":8027589,"ph":"X","dur":150,"name":"OptFunction","args":{"detail":"_RNvCscSpY9Juk0HT_7___rustc26___rust_alloc_error_handler"}}
{"pid":25,"tid":35,"ts":31457262,"ph":"X","dur":24576,"name":"OptFunction","args":{"detail":"_ZN10serde_json5value8to_value17h0315c73febebe85cE"}}
{"pid":25,"tid":35,"ts":31481850,"ph":"X","dur":11862,"name":"OptFunction","args":{"detail":"_ZN10serde_json5value8to_value17h0516143613516496E"}}
{"pid":25,"tid":35,"ts":31493764,"ph":"X","dur":15830,"name":"OptFunction","args":{"detail":"_ZN10serde_json5value8to_value17h0bdb4ac12d8ad59bE"}}
{"pid":25,"tid":35,"ts":31509615,"ph":"X","dur":8221,"name":"OptFunction","args":{"detail":"_ZN10serde_json5value8to_value17h0c630b789ee318c2E"}}
{"pid":25,"tid":35,"ts":31517858,"ph":"X","dur":8670,"name":"OptFunction","args":{"detail":"_ZN10serde_json5value8to_value17h12ba815471bb2bc8E"}}
In its raw form, each of the events' .args.detail field has the mangled symbol of the function being optimized. We can
"demangle" these back to the original Rust symbols with rustfilt — for example:
$ cargo install rustfilt
$ rustfilt '_RNvCscSpY9Juk0HT_7___rustc12___rust_alloc'
__rustc::__rust_alloc
$ rustfilt '_ZN10serde_json5value8to_value17h0315c73febebe85cE'
serde_json::value::to_value
It's worth noting that in the list above, while there's several serde_json::value::to_value items, they actually have
distinct hashes:
$ rustfilt -h '_ZN10serde_json5value8to_value17h0315c73febebe85cE'
serde_json::value::to_value::h0315c73febebe85c
$ rustfilt -h '_ZN10serde_json5value8to_value17h0516143613516496E'
serde_json::value::to_value::h0516143613516496
$ rustfilt -h '_ZN10serde_json5value8to_value17h0bdb4ac12d8ad59bE'
serde_json::value::to_value::h0bdb4ac12d8ad59b
$ rustfilt -h '_ZN10serde_json5value8to_value17h0c630b789ee318c2E'
serde_json::value::to_value::h0c630b789ee318c2
$ rustfilt -h '_ZN10serde_json5value8to_value17h12ba815471bb2bc8E'
serde_json::value::to_value::h12ba815471bb2bc8
... which makes sense, given that serde_json::value::to_value is a generic function — it might be that it's being
optimized with different generic parameters ("monomorphizations").
Wait, why are we optimizing functions from other crates?
The short answer is that optimization is done in the context of the crate where a function is monomorphized. So if we
define a type Foo and then call methods on Option<Foo>, those methods with those types will first exist in the
context of our crate — meaning it gets compiled and optimized with the same configuration as our crate.
With some knowledge about how the compiler works under the hood, this should hopefully make some sense — but from the outside, it's certainly a little odd!
What's actually taking so long?
Now that we know what we're looking at, we can start doing some analysis. For example, by finding the individual functions we spent the most time optimizing:
$ cat web_http_server.llvm_timings.jsonl \
| jq -c 'select(.name == "OptFunction")' \
| jq -sc 'sort_by(-.dur) | .[] | { dur: (.dur / 1e6), detail: .args.detail }' \
| head
{"dur":1.875744,"detail":"_ZN15web_http_server6photos11PhotosState3new28_$u7b$$u7b$closure$u7d$$u7d$17ha4de409b0951d78bE"}
{"dur":1.44252,"detail":"_ZN14tokio_postgres6client6Client5query28_$u7b$$u7b$closure$u7d$$u7d$17h18fb9179bb73bfa4E"}
{"dur":1.440186,"detail":"_ZN15web_http_server3run28_$u7b$$u7b$closure$u7d$$u7d$17h426fe76bd1b089abE"}
{"dur":1.397705,"detail":"_ZN15web_http_server6photos11PhotosState3new28_$u7b$$u7b$closure$u7d$$u7d$17ha4de409b0951d78bE"}
{"dur":1.170948,"detail":"_ZN14tokio_postgres11connect_raw11connect_raw28_$u7b$$u7b$closure$u7d$$u7d$17h0dfcfa0a648a93f8E"}
{"dur":1.158111,"detail":"_ZN14pulldown_cmark5parse15Parser$LT$F$GT$19handle_inline_pass117hc91a3dc90e0e9e0cE"}
{"dur":1.131707,"detail":"_ZN129_$LT$axum..boxed..MakeErasedHandler$LT$H$C$S$GT$$u20$as$u20$axum..boxed..ErasedIntoRoute$LT$S$C$core..convert..Infallible$GT$$GT$9clone_box17he7f38a2ccd053fbbE"}
{"dur":1.062162,"detail":"_ZN4core3ptr49drop_in_place$LT$http..extensions..Extensions$GT$17h89b138bb6c1aa101E"}
{"dur":1.026656,"detail":"_ZN15web_http_server3run28_$u7b$$u7b$closure$u7d$$u7d$17h426fe76bd1b089abE"}
{"dur":1.009844,"detail":"_ZN4core3ptr252drop_in_place$LT$$LT$alloc..vec..drain..Drain$LT$T$C$A$GT$$u20$as$u20$core..ops..drop..Drop$GT$..drop..DropGuard$LT$lol_html..selectors_vm..stack..StackItem$LT$lol_html..rewriter..rewrite_controller..ElementDescriptor$GT$$C$alloc..alloc..Global$GT$$GT$17h62ca0c07fce3ede0E"}
(Why two separate jq invocations? If we did just one, the -s/--slurp call would load the entire file
into a single array before any processing, which is one of the key operations we're trying to avoid)
This is a surprising amount of time on individual functions! Profiling roughly doubled the total time to compile, but even 1 second optimizing a single function is quite a long time!
But let's look into more detail here. We've got:
web_http_server::photos::PhotosState::new::{{closure}}— this is some closure inside a giant, 400-line async function that does the setup for https://sharnoff.io/photosweb_http_server::run::{{closure}}— this is inside the main entrypoint (also async), but all the closures are small error-handling, like.wrap_err_with(|| format!("failed to bind address {addr:?}"))- Maybe there's something weird going on here!
... and a handful of dependencies that also took a while:
pulldown_cmarkhas a 500-line function that's generic over a callbacktokio_postgres::connect_rawis a simple closure inside a reasonably-sized async function – maybe this is for the same reason as the closure in myweb_http_server::run?- The drop implementation of
http::extensions::Extensionslooks like it should be simple (there's no explicit destructor), but internally it'sOption<Box<HashMap<TypeId, Box<dyn ...>, BuildDefaultHasher<..>>>>. Maybe there's a lot of complexity from inlining here? - And dropping
vec::Drain<T>with a series of nestedlol_htmltypes also complains – maybe for similar reasons
Alternately, we could break it down by the outermost crate:
$ cat web_http_server.llvm_timings.jsonl \
| jq -r 'select(.name == "OptFunction") | "\(.dur) \(.args.detail)"' \
| xargs -l bash -c 'echo "{\"dur\":$0,\"root\":\"$(rustfilt "$1" | sed -E "s/^([a-z_-]+)::.*/\1/g")\"}"' \
| jq -s -r 'group_by(.root) | map({ root: .[0].root, dur: (map(.dur) | add) }) | sort_by(-.dur) | .[] | "\(.dur / 1e6) \(.root)"' \
| head
61.534452 core
13.750173 web_http_server
11.237289 tokio
7.890088 tokio_postgres
6.851621 lol_html
4.470053 alloc
4.177471 feed_rs
3.269217 std
3.067573 hashbrown
3.063146 eyre
This is, of course, a very imperfect measure — the outermost crate isn't necessarily the best one to attribute the
compilation time to, and there's a lot of items like <Foo as Bar>::baz that aren't captured by this simple filtering.
But all that aside, it's still surprising that there's so much from core!
Digging further, 84% of that time is just parameterizations of core::ptr::drop_in_place!
Digging more into closures, with mangling v0
The long compile times for closures seems very suspicious — maybe it's worth digging further. There's just one
problem: the symbols all end with {{closure}} without saying which one is taking all the time.
As it turns out, there's an easy fix! As of June 2025, rustc currently uses the "legacy" symbol mangling format by
default, but there's a newer option with more information: the v0 format.
We can enable it by adding RUSTFLAGS="-C symbol-mangling-version=v0" to our existing flags, which now look something
like:
RUSTC_BOOTSTRAP=1 RUSTFLAGS="-Csymbol-mangling-version=v0 -Zllvm-time-trace" cargo build --timings ...
(aside: The issue for that feature's been open for 6 years, why hasn't it been merged yet? Turns out, there's a lot of
upstream work required to add support in common tools like gdb and perf. A lot of that has been done, but not yet
everything.)
The end result of this is that we get much better symbols coming out of the LLVM trace. As an example, here's what
those serde_json::value::to_value symbols look like now:
$ cat web_http_server.llvm_timings.jsonl | jq -c 'select(.name == "OptFunction")' | grep -E 'serde_json.+value.+to_value' | head
{"pid":25,"tid":35,"ts":34400185,"ph":"X","dur":7336,"name":"OptFunction","args":{"detail":"_RINvNtCs9KWWFfvvCPd_10serde_json5value8to_valueINtNCNvCs5etrU9lJXb7_15web_http_server5index012IndexContextNtNtNtNtBQ_4blog6handle7context9RootIndexNtNtNtNtBQ_6photos6handle7context9RootIndexEEBQ_"}}
{"pid":25,"tid":35,"ts":34407530,"ph":"X","dur":13226,"name":"OptFunction","args":{"detail":"_RINvNtCs9KWWFfvvCPd_10serde_json5value8to_valueNtNtNtNtCs5etrU9lJXb7_15web_http_server4blog6handle7context4PostEBR_"}}
{"pid":25,"tid":35,"ts":34420761,"ph":"X","dur":10344,"name":"OptFunction","args":{"detail":"_RINvNtCs9KWWFfvvCPd_10serde_json5value8to_valueNtNtNtNtCs5etrU9lJXb7_15web_http_server4blog6handle7context5IndexEBR_"}}
{"pid":25,"tid":35,"ts":34431114,"ph":"X","dur":11100,"name":"OptFunction","args":{"detail":"_RINvNtCs9KWWFfvvCPd_10serde_json5value8to_valueNtNtNtNtCs5etrU9lJXb7_15web_http_server6photos6handle7context11AlbumsIndexEBR_"}}
$ rustfilt '_RINvNtCs9KWWFfvvCPd_10serde_json5value8to_valueINtNCNvCs5etrU9lJXb7_15web_http_server5index012IndexContextNtNtNtNtBQ_4blog6handle7context9RootIndexNtNtNtNtBQ_6photos6handle7context9RootIndexEEBQ_'
serde_json::value::to_value::<web_http_server::index::{closure#0}::IndexContext<web_http_server::blog::handle::context::RootIndex, web_http_server::photos::handle::context::RootIndex>>
$ rustfilt '_RINvNtCs9KWWFfvvCPd_10serde_json5value8to_valueNtNtNtNtCs5etrU9lJXb7_15web_http_server4blog6handle7context4PostEBR_'
serde_json::value::to_value::<web_http_server::blog::handle::context::Post>
$ rustfilt '_RINvNtCs9KWWFfvvCPd_10serde_json5value8to_valueNtNtNtNtCs5etrU9lJXb7_15web_http_server4blog6handle7context5IndexEBR_'
serde_json::value::to_value::<web_http_server::blog::handle::context::Index>
$ rustfilt '_RINvNtCs9KWWFfvvCPd_10serde_json5value8to_valueNtNtNtNtCs5etrU9lJXb7_15web_http_server6photos6handle7context11AlbumsIndexEBR_'
serde_json::value::to_value::<web_http_server::photos::handle::context::AlbumsIndex>
So not only do we get better closure labeling (see e.g. {closure#0}) but we also get full generics for everything!
Exactly what's taking so long should be much clearer now:
$ cat web_http_server.llvm_timings.jsonl \
| jq -r 'select(.name == "OptFunction") | "\(.dur) \(.args.detail)"' \
| xargs -l bash -c 'echo "{\"dur\":$0,\"fn\":\"$(rustfilt "$1")\"}"' \
| jq -sr 'sort_by(-.dur) | .[] | "\(.dur / 1e4 | round | . / 1e2)s \(.fn)"' \
| head -n5
1.99s <web_http_server::photos::PhotosState>::new::{closure#0}
1.56s web_http_server::run::{closure#0}
1.41s <web_http_server::photos::PhotosState>::new::{closure#0}
1.22s core::ptr::drop_in_place::<axum::routing::Endpoint<web_http_server::AppState>>
1.15s core::ptr::drop_in_place::<axum::routing::method_routing::MethodEndpoint<web_http_server::AppState, core::convert::Infallible>>
... but those first few closures are tiny:
let is_jpg = |path: &Path| path.extension().and_then(|s| s.to_str()) == Some("jpg");
and
let app = axum::Router::new()
/* .route(...) for many others */
.route("/feed.xml", axum::routing::get(move || async move { feed }))
// this one: ^^^^^^^^^^^^^^^^^^^^^^^^^^^
And if we remove these closures, replacing them with separately defined functions where possible, LLVM still reports
taking a long time to optimize {closure#0} in the outer function.
So where are those closures coming from?
After dumping the LLVM IR with RUSTFLAGS="--emit=llvm-ir" (which places it into target/.../deps/*.ll) and searching
through the generated functions, I found a line like:
; core::ptr::drop_in_place::<<web_http_server::photos::PhotosState>::new::{closure#0}::process_photo::{closure#0}>
That process_photo function was a nested async function, defined directly inside PhotosState::new — so why did the
symbol say it was defined inside a closure?
It's because rustc internally represents async functions/blocks with a nested closure. So all of these places that
we had async functions where compiling closure#0 took a long time were actually just referring to the function itself!
With some quick github searching (is:issue state:open async fn closure mangle), it turned out there was already an
open issue about this!
Big async functions considered harmful?
Going back to our list from before – those async functions where LLVM takes a long time to optimize closure#0 are
really just spending a long time on the body of the function itself. It would make sense that big functions are hard to
optimize, and async functions doubly so.
It's fairly straightforward to identify all of the functions inside the main crate that are taking a long time:
$ cat web_http_server.llvm_timings.jsonl \
| jq -r 'select(.name == "OptFunction") | "\(.dur) \(.args.detail)"' \
| xargs -l bash -c 'echo "{\"dur\":$0,\"fn\":\"$(rustfilt "$1")\"}"' \
| jq -sc 'group_by(.fn) | map({ fn: .[0].fn, dur: (map(.dur) | add) }) | sort_by(-.dur) | .[]' \
| jq -r 'select(.fn | test("^(core::ptr::drop_in_place::<)?<*web_http_server")) | "\(.dur / 1e4 | round | . / 1e2)s \(.fn)"' \
| head -n10
4.11s <web_http_server::photos::PhotosState>::new::{closure#0}
3.05s web_http_server::run::{closure#0}
1.44s core::ptr::drop_in_place::<web_http_server::run::{closure#0}>
0.6s <web_http_server::reading_list::handle::post_login as axum::handler::Handler<(axum_core::extract::private::ViaRequest, axum::extract::state::State<&web_http_server::reading_list::ReadingListState>, axum::extract::state::State<&tera::tera::Tera>, axum_extra::extract::cookie::CookieJar, axum::form::Form<web_http_server::reading_list::handle::LoginForm>), web_http_server::AppState>>::call::{closure#0}
0.57s web_http_server::reading_list::fetch_posts_data::{closure#0}
0.51s <web_http_server::reading_list::ReadingListState>::make_pool::{closure#0}
0.44s <web_http_server::reading_list::ReadingListState>::refresh_single::{closure#0}
0.38s <web_http_server::photos::PhotosState>::process_photo::{closure#0}
0.38s <web_http_server::html::WriteState>::process_event
0.33s core::ptr::drop_in_place::<<web_http_server::reading_list::ReadingListState>::run_refresh::{closure#0}::{closure#0}>
Some of the most expensive functions here are around setup.
Let's try breaking up just one function, to see if it helps. We'll start with PhotosState::new.
before any changes: full timings for PhotosState::new
$ cat web_http_server.llvm_timings.jsonl \
| jq -r 'select(.name == "OptFunction") | "\(.dur) \(.args.detail)"' \
| xargs -l bash -c 'echo "{\"dur\":$0,\"fn\":\"$(rustfilt "$1")\"}"' \
| jq -sc 'group_by(.fn) | map({ fn: .[0].fn, dur: (map(.dur) | add) }) | sort_by(-.dur) | .[]' \
| jq 'select(.fn | test("^(core::ptr::drop_in_place::<)?<web_http_server::photos::PhotosState>::new")) | .dur' \
| jq -sr 'add | . / 1e4 | round | . / 1e2 | "\(.)s"'
5.3s
$ cat web_http_server.llvm_timings.jsonl \
| jq -r 'select(.name == "OptFunction") | "\(.dur) \(.args.detail)"' \
| xargs -l bash -c 'echo "{\"dur\":$0,\"fn\":\"$(rustfilt "$1")\"}"' \
| jq -sc 'group_by(.fn) | map({ fn: .[0].fn, dur: (map(.dur) | add) }) | sort_by(-.dur) | .[]' \
| jq -r 'select(.fn | test("^(core::ptr::drop_in_place::<)?<web_http_server::photos::PhotosState>::new")) | "\(.dur / 1e4 | round | . / 1e2)s \(.fn)"'
4.11s <web_http_server::photos::PhotosState>::new::{closure#0}
0.27s core::ptr::drop_in_place::<<web_http_server::photos::PhotosState>::new::{closure#0}>
0.24s core::ptr::drop_in_place::<<web_http_server::photos::PhotosState>::new::{closure#0}::{closure#2}::{closure#0}>
0.23s core::ptr::drop_in_place::<<web_http_server::photos::PhotosState>::new::{closure#0}::{closure#2}>
0.19s core::ptr::drop_in_place::<<web_http_server::photos::PhotosState>::new::{closure#0}::{closure#6}::{closure#0}>
0.11s core::ptr::drop_in_place::<<web_http_server::photos::PhotosState>::new::{closure#0}::{closure#7}::{closure#0}>
0.03s <web_http_server::photos::PhotosState>::new::{closure#0}::{closure#6}::{closure#0}
0.02s <web_http_server::photos::PhotosState>::new::{closure#0}::{closure#3}
0.02s <web_http_server::photos::PhotosState>::new::{closure#0}::{closure#11}
0.02s <web_http_server::photos::PhotosState>::new::{closure#0}::{closure#4}
0.02s <web_http_server::photos::PhotosState>::new::{closure#0}::{closure#5}
0.01s <web_http_server::photos::PhotosState>::new::{closure#0}::{closure#2}
0.01s <web_http_server::photos::PhotosState>::new::{closure#0}::{closure#7}::{closure#0}
0.01s <web_http_server::photos::PhotosState>::new::{closure#0}::{closure#2}::{closure#0}
0.01s <web_http_server::photos::PhotosState>::new::{closure#0}::{closure#1}::{closure#1}
On the first attempt, I tried breaking it up while also preserving the number of .awaits – it's easy to do both
accidentally, and this would hopefully isolate which type of complexity is causing problems.
After naive splitting: full timings for photos::init
$ cat web_http_server.llvm_timings.jsonl \
| jq -r 'select(.name == "OptFunction") | "\(.dur) \(.args.detail)"'
| xargs -l bash -c 'echo "{\"dur\":$0,\"fn\":\"$(rustfilt "$1")\"}"' \
| jq -sc 'group_by(.fn) | map({ fn: .[0].fn, dur: (map(.dur) | add) }) | sort_by(-.dur) | .[]' \
| jq 'select(.fn | test("^(core::ptr::drop_in_place::<)?<*web_http_server::photos::(init|PhotosState>::new)")) | .dur' \
| jq -sr 'add | . / 1e4 | round | . / 1e2 | "\(.)s"'
4.66s
$ cat web_http_server.llvm_timings.jsonl \
| jq -r 'select(.name == "OptFunction") | "\(.dur) \(.args.detail)"' \
| xargs -l bash -c 'echo "{\"dur\":$0,\"fn\":\"$(rustfilt "$1")\"}"' \
| jq -sc 'group_by(.fn) | map({ fn: .[0].fn, dur: (map(.dur) | add) }) | sort_by(-.dur) | .[]' \
| jq -r 'select(.fn | test("^(core::ptr::drop_in_place::<)?<*web_http_server::photos::(init|PhotosState>::new)")) | "\(.dur / 1e4 | round | . / 1e2)s \(.fn)"'
3.37s web_http_server::photos::init::make_state::{closure#0}
0.24s core::ptr::drop_in_place::<web_http_server::photos::init::image_process_futs::{closure#0}::{closure#0}>
0.21s core::ptr::drop_in_place::<web_http_server::photos::init::album_process_futs::{closure#0}>
0.21s core::ptr::drop_in_place::<web_http_server::photos::init::make_state::{closure#0}>
0.16s core::ptr::drop_in_place::<web_http_server::photos::init::image_process_futs::{closure#0}>
0.12s core::ptr::drop_in_place::<web_http_server::photos::init::album_process_futs::{closure#1}>
0.06s web_http_server::photos::init::album_process_futs::{closure#0}
0.04s web_http_server::photos::init::image_process_futs::{closure#0}
0.03s web_http_server::photos::init::album_process_futs::{closure#1}
0.03s web_http_server::photos::init::album_process_futs
0.02s core::ptr::drop_in_place::<web_http_server::photos::init::get_img_candidates::{closure#0}>
0.02s web_http_server::photos::init::make_album_membership
0.02s web_http_server::photos::init::make_state::{closure#0}::{closure#1}
0.02s web_http_server::photos::init::make_albums_in_order
0.02s web_http_server::photos::init::image_process_futs
0.02s web_http_server::photos::init::make_state::{closure#0}::{closure#3}
0.02s web_http_server::photos::init::make_state::{closure#0}::{closure#2}
0.02s web_http_server::photos::init::image_process_futs::{closure#0}::{closure#0}
0.02s web_http_server::photos::init::make_state::{closure#0}::{closure#7}
0.01s web_http_server::photos::init::make_all_album
0.01s web_http_server::photos::init::make_recently_published_albums
0.01s web_http_server::photos::init::make_images_by_time
0s web_http_server::photos::init::get_img_candidates::{closure#0}::{closure#1}::{closure#1}
Interestingly, this didn't help all that much: only reducing the total time from 5.3s to 4.7s.
So to add to that, I tried merging a handful of neighboring .awaits into their own functions — reducing the total
number from 10 to 3.
After grouping .awaits
$ cat web_http_server.llvm_timings.jsonl \
| jq -r 'select(.name == "OptFunction") | "\(.dur) \(.args.detail)"'
| xargs -l bash -c 'echo "{\"dur\":$0,\"fn\":\"$(rustfilt "$1")\"}"' \
| jq -sc 'group_by(.fn) | map({ fn: .[0].fn, dur: (map(.dur) | add) }) | sort_by(-.dur) | .[]' \
| jq 'select(.fn | test("^(core::ptr::drop_in_place::<)?<*web_http_server::photos::(init|PhotosState>::new)")) | .dur' \
| jq -sr 'add | . / 1e4 | round | . / 1e2 | "\(.)s"'
6.24s
$ cat web_http_server.llvm_timings.jsonl \
| jq -r 'select(.name == "OptFunction") | "\(.dur) \(.args.detail)"' \
| xargs -l bash -c 'echo "{\"dur\":$0,\"fn\":\"$(rustfilt "$1")\"}"' \
| jq -sc 'group_by(.fn) | map({ fn: .[0].fn, dur: (map(.dur) | add) }) | sort_by(-.dur) | .[]' \
| jq -r 'select(.fn | test("^(core::ptr::drop_in_place::<)?<*web_http_server::photos::(init|PhotosState>::new)")) | "\(.dur / 1e4 | round | . / 1e2)s \(.fn)"'
2.7s web_http_server::photos::init::process_all_images::{closure#0}
1.93s web_http_server::photos::init::make_state::{closure#0}
0.25s core::ptr::drop_in_place::<web_http_server::photos::init::image_process_futs::{closure#0}::{closure#0}>
0.25s core::ptr::drop_in_place::<web_http_server::photos::init::album_process_futs::{closure#0}>
0.18s core::ptr::drop_in_place::<web_http_server::photos::init::image_process_futs::{closure#0}>
0.14s core::ptr::drop_in_place::<web_http_server::photos::init::album_process_futs::{closure#1}>
0.09s core::ptr::drop_in_place::<web_http_server::photos::init::process_all_images::{closure#0}>
0.08s core::ptr::drop_in_place::<web_http_server::photos::init::join_image_futs<web_http_server::photos::init::image_process_futs::{closure#0}>::{closure#0}>
0.07s core::ptr::drop_in_place::<web_http_server::photos::init::make_state::{closure#0}>
0.07s web_http_server::photos::init::album_process_futs::{closure#0}
0.06s core::ptr::drop_in_place::<web_http_server::photos::init::parse::{closure#0}>
0.04s core::ptr::drop_in_place::<web_http_server::photos::init::join_album_futs::{closure#0}>
0.04s web_http_server::photos::init::image_process_futs::{closure#0}
0.03s web_http_server::photos::init::album_process_futs
0.03s web_http_server::photos::init::make_album_membership
0.03s core::ptr::drop_in_place::<web_http_server::photos::init::get_img_candidates::{closure#0}>
0.03s web_http_server::photos::init::album_process_futs::{closure#1}
0.03s web_http_server::photos::init::make_albums_in_order
0.03s web_http_server::photos::init::image_process_futs
0.02s web_http_server::photos::init::process_all_images::{closure#0}::{closure#1}
0.02s web_http_server::photos::init::make_state::{closure#0}::{closure#0}
0.02s web_http_server::photos::init::make_state::{closure#0}::{closure#1}
0.02s web_http_server::photos::init::process_all_images::{closure#0}::{closure#2}
0.02s web_http_server::photos::init::image_process_futs::{closure#0}::{closure#0}
0.02s web_http_server::photos::init::make_all_album
0.01s web_http_server::photos::init::make_images_by_time
0.01s web_http_server::photos::init::make_recently_published_albums
0s web_http_server::photos::init::get_img_candidates::{closure#0}::{closure#1}::{closure#1}
But that took substantially longer! It increased from 4.66s to 6.24s!
At this point, it seemed like there was something strange happening with async functions. Otherwise, why would splitting into more functions make things worse?
Under the hood, async functions desugar to a complex state machine. There might be something odd happening there, so if
we want to make that simpler in the caller, we can turn the Future into a trait object to obscure the implementation
behind it (typically Pin<Box<dyn Future>>).
So this time, let's add a new function like:
fn erase<'a, T>(
fut: impl 'a + Send + Future<Output = T>,
) -> Pin<Box<dyn 'a + Send + Future<Output = T>>> {
Box::pin(fut)
}
and using it everywhere we .await. For example:
// old:
let candidates = get_img_candidates().await?;
// new:
let candidates = erase(get_img_candidates()).await?;
Final change: Pin> the futures
$ cat web_http_server.llvm_timings.jsonl \
| jq -r 'select(.name == "OptFunction") | "\(.dur) \(.args.detail)"'
| xargs -l bash -c 'echo "{\"dur\":$0,\"fn\":\"$(rustfilt "$1")\"}"' \
| jq -sc 'group_by(.fn) | map({ fn: .[0].fn, dur: (map(.dur) | add) }) | sort_by(-.dur) | .[]' \
| jq 'select(.fn | test("^(core::ptr::drop_in_place::<)?<*web_http_server::photos::(init|PhotosState>::new)")) | .dur' \
| jq -sr 'add | . / 1e4 | round | . / 1e2 | "\(.)s"'
2.14s
$ cat web_http_server.llvm_timings.jsonl \
| jq -r 'select(.name == "OptFunction") | "\(.dur) \(.args.detail)"' \
| xargs -l bash -c 'echo "{\"dur\":$0,\"fn\":\"$(rustfilt "$1")\"}"' \
| jq -sc 'group_by(.fn) | map({ fn: .[0].fn, dur: (map(.dur) | add) }) | sort_by(-.dur) | .[]' \
| jq -r 'select(.fn | test("^(core::ptr::drop_in_place::<)?<*web_http_server::photos::(init|PhotosState>::new)")) | "\(.dur / 1e4 | round | . / 1e2)s \(.fn)"'
0.25s web_http_server::photos::init::process_all_images::{closure#0}
0.21s core::ptr::drop_in_place::<web_http_server::photos::init::image_process_futs::{closure#0}::{closure#0}>
0.2s core::ptr::drop_in_place::<web_http_server::photos::init::image_process_futs::{closure#0}>
0.2s web_http_server::photos::init::join_image_futs::<web_http_server::photos::init::image_process_futs::{closure#0}>::{closure#0}
0.19s core::ptr::drop_in_place::<web_http_server::photos::init::album_process_futs::{closure#0}>
0.13s web_http_server::photos::init::parse::{closure#0}
0.11s core::ptr::drop_in_place::<web_http_server::photos::init::album_process_futs::{closure#1}>
0.1s web_http_server::photos::init::get_img_candidates::{closure#0}
0.1s core::ptr::drop_in_place::<web_http_server::photos::init::make_state::{closure#0}>
0.06s core::ptr::drop_in_place::<web_http_server::photos::init::process_all_images::{closure#0}>
0.06s web_http_server::photos::init::album_process_futs::{closure#0}
0.06s web_http_server::photos::init::album_process_futs
0.05s web_http_server::photos::init::join_album_futs::{closure#0}
0.05s web_http_server::photos::init::make_albums_in_order
0.05s core::ptr::drop_in_place::<web_http_server::photos::init::join_image_futs<web_http_server::photos::init::image_process_futs::{closure#0}>::{closure#0}>
0.04s core::ptr::drop_in_place::<web_http_server::photos::init::parse::{closure#0}>
0.03s web_http_server::photos::init::image_process_futs::{closure#0}
0.03s web_http_server::photos::init::make_all_album
0.03s web_http_server::photos::init::album_process_futs::{closure#1}
0.02s core::ptr::drop_in_place::<web_http_server::photos::init::join_album_futs::{closure#0}>
0.02s core::ptr::drop_in_place::<web_http_server::photos::init::get_img_candidates::{closure#0}>
0.02s web_http_server::photos::init::make_state::{closure#0}::{closure#1}
0.02s web_http_server::photos::init::make_state::{closure#0}::{closure#0}
0.02s web_http_server::photos::init::make_recently_published_albums
0.02s web_http_server::photos::init::image_process_futs::{closure#0}::{closure#0}
0.01s web_http_server::photos::init::make_images_by_time
0.01s web_http_server::photos::init::erase::<core::result::Result<std::collections::hash::map::HashMap<alloc::string::String, &web_http_server::photos::Album>, eyre::Report>, web_http_server::photos::init::join_album_futs::{closure#0}>
0.01s web_http_server::photos::init::erase::<core::result::Result<web_http_server::photos::init::ProcessedImages, eyre::Report>, web_http_server::photos::init::process_all_images::{closure#0}>
0.01s web_http_server::photos::init::erase::<core::result::Result<(web_http_server::photos::MapSettings, web_http_server::photos::FlexGridSettings, web_http_server::photos::parsed::HiddenAlbumsAndPhotos, web_http_server::photos::parsed::Albums), eyre::Report>, web_http_server::photos::init::parse::{closure#0}>
0.01s web_http_server::photos::init::process_all_images::{closure#0}::{closure#1}
0.01s web_http_server::photos::init::process_all_images::{closure#0}::{closure#2}
0.01s web_http_server::photos::init::make_state
0.01s web_http_server::photos::init::get_img_candidates::{closure#0}::{closure#1}::{closure#1}
This one worked — down to 2.14s.
So, a reduction from 5.3s to 2.14s – a notable improvement, albeit with a lot of effort to get there. (and, for the
record, when I wrapped the futures with Box::pin instead of a fresh function, it didn't make a difference here).
Re-running the build without profiling, this gives a total reduction from 48.8s to 46.8s. It's pretty small, but that's from just a single function!
(Aside: What about #[inline(never)]? I tried it with and without – after boxing, compile times weren't any better
with inlining disabled for those functions, but it's still helpful for ensuring better attribution on the LLVM
timings.)
(Aside: What about disabling inlining on the poll functions? I also tried wrapping the async functions with a
Future implementation having #[inline(never)] on its poll function. That helped some, but wasn't as good as
boxing.)
Putting it together
There's a number of approaches available — let's try:
- Reducing inlining with LLVM args;
- Breaking up expensive functions in the main crate; and
- Removing generics from dependencies to prevent needing to compile it in the main crate
So, updating the final Dockerfile commands to read:
RUN RUSTFLAGS='-Cllvm-args=-inline-threshold=10 -Cllvm-args=-inlinedefault-threshold=10 -Cllvm-args=-inlinehint-threshold=10' \
cargo chef cook --release --target=x86_64-unknown-linux-musl --recipe-path=/workdir/recipe.json
...
RUN RUSTFLAGS='-Cllvm-args=-inline-threshold=10 -Cllvm-args=-inlinedefault-threshold=10 -Cllvm-args=-inlinehint-threshold=10' \
cargo build --timings --release --target=x86_64-unknown-linux-musl --package web-http-server
... and many more small changes to the main crate:
$ git diff --stat base..HEAD -- web-http-server
...
10 files changed, 898 insertions(+), 657 deletions(-)
... alongside some changes to larger dependencies:
- Making a generic function non-generic: https://github.com/pulldown-cmark/pulldown-cmark/pull/1045
- Building a separate crate with non-generic versions: changes in
cargo-chef, with a new local crate exposing non-generic versions of the APIs I use fromlol_htmlanddeadpool_postgres
... gives us a final compile time of 32.3s.
Update 2025-06-27
The plot thickens!
After I shared this post, a couple folks on Bluesky gave some good tips!
- Enabling
-Zshare-generics; and - Switching away from Alpine
Enabling -Zshare-generics
Piotr Osiewicz on Bluesky suggested enabling -Zshare-generics:
It'll reuse instantiations of generics from the dependencies of a crate. It is not enabled for release builds (by default), as it has a negative impact on codegen.
[ ... ]
The flag is available only on nightly, but it is enabled for dev builds even when using a stable tool chain.
Sounds neat! Let's try enabling it!
RUSTFLAGS="-Zshare-generics -Cllvm-args=-inline-threshold=10 -Cllvm-args=-inlinedefault-threshold=10 -Cllvm-args=-inlinehint-threshold=10" ...
The end result is interesting — a drop in total compile time from 32.3s to 29.1s, even though many of the
core::ptr::drop_in_places that we were compiling before are still present.
Looking at the biggest times, filtering just for drop_in_place for concrete types exposed by other crates:
$ # Before
$ cat ... | jq ... \
| grep -P 'core::ptr::drop_in_place::<(?!web_http_server)[a-zA-Z0-9_:]+>$' \
| head -n5
0.42s core::ptr::drop_in_place::<tracing_subscriber::filter::directive::ParseError>
0.13s core::ptr::drop_in_place::<http::uri::Uri>
0.12s core::ptr::drop_in_place::<toml_edit::item::Item>
0.11s core::ptr::drop_in_place::<std::io::error::Error>
0.1s core::ptr::drop_in_place::<hyper::body::incoming::Incoming>
$ # After
$ cat ... | jq ... \
| grep -P 'core::ptr::drop_in_place::<(?!web_http_server)[a-zA-Z0-9_:]+>$' \
| head -n5
0.59s core::ptr::drop_in_place::<hyper::ext::Protocol>
0.28s core::ptr::drop_in_place::<http::header::map::HeaderMap>
0.1s core::ptr::drop_in_place::<std::io::error::Error>
0.09s core::ptr::drop_in_place::<http::uri::Uri>
0.08s core::ptr::drop_in_place::<tokio::runtime::io::registration::Registration>
There's some change between them, but it's still compiling the same core::ptr::drop_in_place for a lot of
dependencies!
In spite of that though, the optimization time decreased substantially — from 21.7s to 17.4s if you look just at the
drop_in_place instantiations, and far more if you look at everything together (128s to 104s; across multiple threads,
with LLVM profiling's overhead).
Switching away from Alpine
Wesley Moore on Lobsters (via Bluesky) suggested switching away from Alpine, due to the impact that the default allocator can have on compile times:
In my experience the allocator can have a big impact on build times. For example when Chimera Linux switched from scudo (which was already better than the default musl allocator) to mimalloc a clean build of Gleam went from 67s to 46s.
Similar results can be observed by switching the base image of a build in docker [ ... ]
This made a huge difference.
After switching out alpine for debian and removing the --target=x86_64-unknown-linux-musl, the total compile time
dropped from 29.1s all the way down to 9.1s!
Final recap
- We started at ~175s
- Disabling LTO (and debug symbols!) got us to 51s (-71%)
- Changing to
opt-level = 1on the final crate got us to 48.8s (-4%) - Reducing inlining with
-C llvm-argsgot us to 40.7s (-16%) - Local changes got us to 37.7s (-7%)
- Changes with dependencies got us to 32.3s (-14%)
Updated 2025-06-27:
- Enabling
-Zshare-genericsgot us to 29.1s (-10%) - And switching away from alpine got us to 9.1s (-69%)
What now?
While I did hit a lot of issues here, the tooling honestly worked really well – and the documentation was sufficient for someone with relatively little experience to make meaningful improvements to their codebase.
Some of the issues are straightforward: bugfixes to provide a nicer experience for the next person that finds themselves in a similar mess.
Others are more complicated:
-
The compile time of deep call graphs of async functions needs to be improved – perhaps LLVM has a degenerate edge case that's easy to trigger with what
rustcgenerates, or maybe it's as simple as a bad heuristic that's under-utilized in other languages. -
It might be worthwhile for
rustcto special-casecore::ptr::drop_in_place<T>so that it's compiled in the crate that definesT. That approach wouldn't work for everything – for example, generic types – but it would prevent downstream crates from needing to re-compile the same destructor multiple times.-
Update 2025-06-27:
-Zshare-genericsdoes help here, but it's not a complete fix. In the meantime, however, I found that this is actually something that's been previously discussed — unfortunately it seems like it causes severe increases in compile time due to compiling all the drop glue that would otherwise be unused. It's possible that there's some middle ground here (e.g., signaling that you want to prioritize compile times of the final binary to the detriment of the dependencies), but it's hard to say what the right approach is.
-
-
There might also be room for tooling to help with isolating which parts of a codebase are taking up the most time during compilation (and providing recommendations to mitigate) – although that's a longer project than just this post.
In the meantime, setting opt-level = 0 might be just fine :)
(questions? comments? Feel free to reach out below!)